How can I benefit?
EERAdata has identified the prime FAIR data needs of different stakeholder groups, and hightlights the necessity of advancing FAIR metadata standards in the low-carbon energy research community (Wierling et al. 2021).
At the same time, producers of energy data will increase their impact: FAIR data receive more scientific citations and create more impact in economic terms.
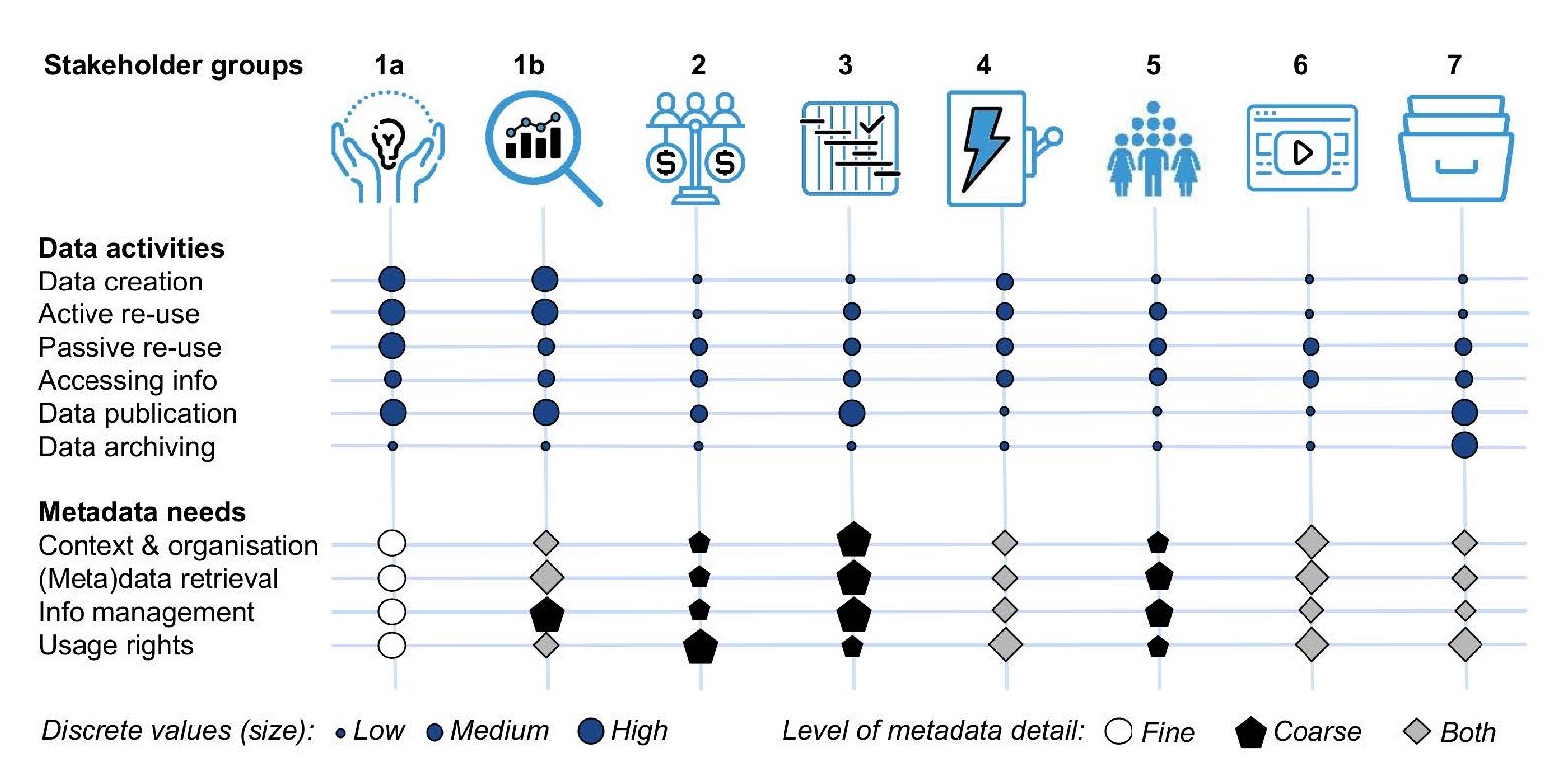
FAIR data addresses the various needs of the different stakeholder groups:
1a) Energy domain experts create data from scratch, re-use existing data to curate, aggregate, analyze, and publish data. They come from various disciplines. As re-users of data, they need support from metadata in searching and finding data. They require context information with high granularity and rich provenance to assess data quality and relevance, precise information on usage rights, and intellectual property rights (IPR) requirements.
1b) Interdisciplinary scientists inform themselves on (other) expert knowledge, re-use data, aggregate and analyze data, and publish data. They require context information for searching and finding data. They need information on the context of data and provenance (mostly on aggregated levels) and precise information on usage rights and IPR. Shared and open data fall within the interest of this group.
Science funders of energy R&D activities inform themselves of the results of funded research and projects. They need to monitor, adjust, and plan funding policies and principles to better direct R&D investments and to ensure the impact of policy measures. Evaluation agencies are a key mediator in this regard as they compile existing (meta)data and develop evaluation tools. Another important objective of funders is to unlock the potential of added value by exploring knowledge generated by research, exploiting and expanding its use. Therefore, funding agencies also require the Data Management Plan (DMP) to track data’s provenance and future maintenance. Typically, this application is at a high level of aggregation, and information should be easy to understand and disseminate. Last but not least, a pivotal interest is that the funding agency be acknowledged in the metadata.
Planners and decision-makers (incl. energy market regulators, security coordinators, policy-makers) inform themselves on expert knowledge. They may reuse data, analyze some data, and publish aggregated data and decisions. This involves a middle to high level of aggregation, information on the context of data, and provenance. An important aspect is the metadata information on aggregated data. While this group has an interest in open data policies, they are also obliged to protect private data pertaining to citizens.
Energy and other industries´ stakeholders (incl. technical and operational planners and decisionmakers, energy market operators) inform themselves on expert knowledge and re-use and analyze some data on all aggregation levels. They require information on the context and provenance of data. Important is metadata information on aggregated data. To assess the commercialization potential, legally secure information on usage rights and IPR are needed.
The group informs itself to adjust behavior and practices (e.g., energy consumption behavior, voting in elections, engagement as prosumers, activists or citizen-scientists). They may re-use data to tell others and pose questions leading to research activities. A high level of aggregation is needed to make data easy to understand and navigate.
Data scientists (incl. data engineers, software and algorithm developers) code, test and validate software with existing data. Specifically, data engineers (who may be domain specific or agnostic) are key builders of (meta)data pipelines and back-end solutions. Data scientists may re-use (meta)data to design scientific workflows considering interoperability with other tools and demonstrate applications. They need concise metadata to integrate data sources within the software tool, machine-actionable open file formats, agreed standards, terminologies, and interoperability protocols. Being in legally-compliant control of private data is of particular interest for this user group.
These important groups in the FAIR data ecology publish, store, and archive research data. They may re-use data to link them to metrics such as access statistics and to crossreference. They need metadata regarding ownership/authorship of results or the size of the data and information such as keywords to provide searchability in their publications and archives.