WS2
The second workshop of EERAdata is organized as an online webinar and hackathon during November, 30, to December, 4th, 2020.
Contents
Objective
- Discuss and develop metadata standards for FAIR and open data in the low carbon energy research community.
- Identify gaps and needs that hinder their standardized realization and implementation.
- Jointly work on a community paper and/or join the discussions in use cases. We start with a commented and revised draft. Link to draft of the community paper

Read aheads
Obligatory
Participation in preparatory workshop (or watching the recorded videos). This workshop will take place Thursday, 5th of November, 10-12 CET. The workshop will introduce recent work on metadata, and it will outline the tasks and procedures on how to join the writing team for the community. A draft is open for commenting by 23.11.2020, we highly welcome any feedback! Link to register for the preparatory workshop.
Suggested read on the history of metadata
Metadata - Shaping Knowledge from Antiquity to the Semantic Web by Richard Gartner
Join and collaborate interactively!
Workshop participants are invited to become co-authors of the planned community paper
How to join the team writing the community paper? Briefing is provided during the preparatory workshop (also recorded). Includes recommendation for read and watch aheads.
The community paper addresses 3 key questions:
- Q1: How to align mental models of those searching for data with navigation along metadata? What is specific to the energy domain?
- Q2: What consequences for the construction of domain-specific metadata follow? and how can they be dynamically updated?
- Q3: What are the recommendations to the low carbon community?
The envisaged output of the paper is:
- A community-reviewed draft for a low carbon energy ontology in support of metadata,
- Metadata suggestion cards for low carbon energy researchers,
- Recommendations on how to proceed.
Invitation to comment the draft before the writing workshop, e.g.:
- Review of key questions,
- Suggestions of literature, illustrative cases, metadata perspectives & issues,
- Suggestions to any section (e.g., Introduction, Method, Discussion of Results, Outlook)
- Adding snippets of texts,
Any other idea is welcome!
Using above prior comments & contributions provided by 23.11.2020, the EERAdata team will revise the draft before the workshop starts. During the workshop, the discussion & writing of the paper continues in small writing teams. A prior registration to teams is therefore recommended. However, teams can change anytime. The EERAdata team is strongly interested in inviting a large group of contributing authors. It is not only in the interest of the community project as such, but it increases the credibility of the main output - the draft (or road towards) a low carbon energy ontology in support of metadata”.
Co-authorship is granted to active participants of the EERAdata workshop as well as to other contributors to the community paper.
EERAdata wiki - How to?
The easiest way is you simply start writing and editing. You can install an easy editor by doing what is described in the picture to the right.

Consult the User's Guide for information on using the wiki software.
- Configuration settings list
- MediaWiki FAQ
- MediaWiki release mailing list
- Localise MediaWiki for your language
- Learn how to combat spam on your wiki
EERAdata on github
Link here and share your thoughts and issues! Note, work in progress.
EERAdata @ Research Gate
Link here and share your thoughts and issues! Note, work in progress.
Just have fun!
Metadata memory game
Read before playing: This is a little memory game where players need to identify triples, that is three tiles that belong to one data set. All of them relate to low carbon energy. Some tiles have the form of a picture, others show metadata descriptions (in various formats) and some are even sound files. So, the game is to have fun, while learning about metadata. Try out if you can find all triples. Note if you have opened 3 tiles and they do not match, all will automatically close. Just as you know it from a real-life memory game. Link
Agenda and notes Day 1
Builds on read aheads. Online talks and discussions. Space for interaction with participants after each presentation. Moderated discussion of collected comments.
| Time slot | Topic |
|---|---|
| 10.00-10.20 | Welcome and introduction with workshop goals and procedures: “EERAdata - Towards Utopia for low carbon energy research”, Valeria Jana Schwanitz, HVL & PI EERAdata. Link: [1]. Main points:
|
| 10.20-12.15 | Online lectures:
“The EOSC Nordic: machine-actionable FAIR maturity evaluations & the FAIRification of data repositories” - Andreas Jaunsen, Nordforsk & EOSC-Nordic. Link: [2]. Main points:
“OpenAIRE: Open Access Infrastructure for Research in Europe”, Ilaria Fava, OpenAIRE. Link: [5]. Main points:
A short break of 15 min - “Community-driven metadata and ontologies for Materials Science and their key role in artificial-intelligence tools”, Luca Ghiringhelli, FHI Berlin. Link: [12]. Main points:
“Metadata practices from IRP Wind”, Anna Maria Sempreviva, DTU. Link: [14]. Main points:
|
| 12.15-13.00 | Lunch Break. Play the EERAdata game “Utopia and metadata”. Or any time. |
| 13.00-14.00 | Online lectures:
“Humanities and data: for a community-driven path towards FAIRness”, Elena Giglia, UNITO. Re-using presentation held at the Open Science Conference 2020 in Berlin. Presentation stored at zenodo. Link: [16]. Main points:
“RISIS - An e-Infrastructure for the STI-Policy research community”, Thomas Scherngell, AIT. Link: [17]. Main points:
|
| 14.00-14.30 | Break - Game “Utopia and metadata”. Or any time. |
| 14.30-16.00 | Discussion to compile a to-do list for work in use cases on the second day. Serves as a guiding and aligning process. Lead by WP2, August Wierling/Valeria, HVL. What is the take-to-day-2 message for your use cases?
|
Agenda Day 2
News of the day before
Not energy, but an inspiring connection: Perhaps unexpected, or perhaps even not: DNA helps to puzzle pieces of Qumran role. DNA taken from animal skins that were used to write on ...

FAIR data and FAIR METADATA - DISCUSSIONS in use cases, parallel sessions
Work in use cases on databases and metadata, led by use case leaders. Suggested outline:
- 10-12 Discuss and update the preliminary state of FAIR/O for the use case. Use the prepared draft of databases to check compliance with FAIR principles (tools: WP3 questionnaire and others). Compare the assessment results for each database. Observe and discuss agreements and differences across the evaluation tools. Generate the overall picture for FAIR/O compliance for the use case to pin down the state of art. Let’s see if we come to the same result as in our initial assessment for the application (traffic lights). Continuously make notes to report later on results. Select a responsible person. Objective: select 3-5 databases per use case. Discuss which databases to select. One to cover use-case specific challenges; and one with cross-use case relevance, and one a low hanging fruit for which it would be relatively easy to improve the current FAIR/O status.
- 13-15 Joint brainstorming to discuss FAIR/O state of the metadata for the selected use cases. Evaluate: What is the current description of metadata? How extensive are they? Is only administrative information provided? Or richer context description? What frameworks for metadata are used: taxonomy? thesaurus? ontology? How is the metadata information technically implemented: plain text file? xml? rdf? ... Identify use case specific issues with metadata - What are the gaps? What is perceived as a hard nut to crack? Pay special attention to the metadata of the databases and fill out the table provided WP2. Continuously make notes to report results the next day! Select a responsible person!
- from 15 Joint recordings of lessons learned. Create and/or update the WIKI for the use case with literature, gaps, best practices, FAIR/O discussion, metadata discussion, suggested next steps, .... Get your head around what to report next day! Plan for 20 min. See the links to WIKI page templates below (Notes from Day 2).
Issues identified across use cases
| Use case 1 | Use case 2 | Use case 3 | Use case 4 |
|---|---|---|---|
| Buildings efficiency | Power transmission & distribution networks | Material solutions for low carbon energy | Low carbon energy and energy efficiency policies |
| Gaps & challenges per use case in a nutshell | |||
|
|
|
|
|
Use case 1: Continuously updated summary page UC1, |
Use case 2: Continuously updated summary page UC2, |
Use case 3: Continuously updated summary page UC3, |
Use case 4: Continuously updated summary page UC4, |
Note: This schedule is a suggestion. Adjust and organize breaks as needed.
Special session - FAIR data evaluation by machine
15.30 - 16.00 Andreas Jaunsen, Nordforsk. Presentation of the results from an automated FAIR evaluation for selected repositories suggested by the use cases.
The proposed list of databases to check:
- EUR-Lex: https://eur-lex.europa.eu/homepage.html?locale=en
- JRC: https://data.jrc.ec.europa.eu/
- IEA: https://www.iea.org/policies/about
- Nomad database: https://www.nomad-coe.eu/index.php?page=nomad-repository
- OPSD: https://open-power-system-data.org/
- ENTSO-E Transparency Platform https://transparency.entsoe.eu/
- ExCEED - European Energy Efficient building district Database https://dashboard.exceedproject.eu/
- EU Building Stock Observatory: https://ec.europa.eu/energy/topics/energy-efficiency/energy-efficient-buildings/eu-bso_en
Results Note: 22 indicators with the FAIR Maturity Evaluation Service are tested. 0 stands for "failing the test", 1 stands for "standing the test".
Most of them are a mix of web-pages (of repositories). Thus, a random dataset from a few of them was selected.
| Database link | Result link | Result across 22 indicators | Aggregate result across FAIR categories |
|---|---|---|---|
| https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=OJ:JOC_1999_093_R_0001_01 | https://fair.etais.ee/evaluation/4842 | 1001100001010110000000 | 37.50% 40.00% 28.57% 0.00% 31.82% |
| https://data.jrc.ec.europa.eu/dataset/93d07f10-7757-485f-bb8e-3160536b97f8 | https://fair.etais.ee/evaluation/4843 | 1001110011110110011100 | 0.00% 80.00% 71.43% 0.00% 59.09% |
| https://onlinelibrary.wiley.com/doi/abs/10.1002/aenm.201902830 | https://fair.etais.ee/evaluation/4844 | 1000000001010000000000 | 12.50% 40.00% 0.00% 0.00% 13.64% |
| https://doi.org/10.25832/conventional_power_plants/2018-12-20 | https://fair.etais.ee/evaluation/4845 | 1101110011110110011100 | 62.50% 80.00% 71.43% 0.00% 63.64% |
See also: https://www.rd-alliance.org/groups/fair-data-maturity-model-wg and https://fairsharing.github.io/FAIR-Evaluator-FrontEnd/#!/
Agenda and notes from Day 3
Reporting experience from use case applications. Prepare the next workshop on workflows and metadata. Introduction and discussion of data management plans.
| Time slot | Topic |
|---|---|
| 10-12.00 | Discussion lead by WP2. Report from use case experiences (by use case leaders). Wrap up.
|
| 12-12.30 | Presentation "Some pitfalls in data base licenses", Carsten Hoyer-Klick, DLR - German Aerospace Center. Main points:
|
| 12.30-13.30 | Lunch break |
| 13.30-15.00 | Data Management Plans
Presentation “Introduction to DMP and best practices” by Trond Kvamme, NSD. Link: [21] Main points:
Presentation on Machine-actionable DMPs by Tomasz Miksa, TU Vienna. Link: [27] Main points:
Discussion of EERAdata DMP draft (August, HVL). Main points:
|
| 15.15-16.00 | Wrap up of workshop with feedback from invited experts.
|

WS1 through the lense of an artist

Day 1 No. 1

Day 1 No. 2

Day 1 No. 3

Day 1 No. 4
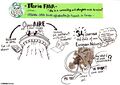
Day 1 No. 5
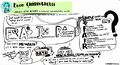
Day 1 No. 6

Day 1 No. 7

Day 1 No. 8

Day 2 No. 1

Day 2 No. 2

Day 2 No. 3

Day 2 No. 4

Day 2 No. 5

Day 3 No. 1

Day 3 No. 2

Day 3 No. 3

Day 3 No. 4

Day 3 No. 5

Day 3 No. 6

Day 3 No. 7















{kind=link}
{kind=link}
{kind=link}
{kind=link}