The second workshop of EERAdata is organized as an online webinar and hackathon during November, 30, to December, 4th, 2020.
Objective
- Discuss and develop metadata standards for FAIR and open data in the low carbon energy research community.
- Identify gaps and needs that hinder their standardized realization and implementation.
- Jointly work on a community paper and/or join the discussions in use cases. We start with a commented and revised draft. Link to draft of the community paper

Workshop concept of EERAdata
Read aheads
Obligatory
Participation in preparatory workshop (or watching the recorded videos). This workshop will take place Thursday, 5th of November, 10-12 CET. The workshop will introduce recent work on metadata, and it will outline the tasks and procedures on how to join the writing team for the community. A draft is open for commenting by 23.11.2020, we highly welcome any feedback! Link to register for the preparatory workshop.
Suggested read on the history of metadata
Metadata - Shaping Knowledge from Antiquity to the Semantic Web by Richard Gartner
Join and collaborate interactively!
Becoming a co-author
Workshop participants are invited to become co-authors of the planned community paper
How to join the team writing the community paper?
Briefing is provided during the preparatory workshop (also recorded). Includes recommendation for read and watch aheads.
The community paper addresses 3 key questions:
- Q1: How to align mental models of those searching for data with navigation along metadata? What is specific to the energy domain?
- Q2: What consequences for the construction of domain-specific metadata follow? and how can they be dynamically updated?
- Q3: What are the recommendations to the low carbon community?
The envisaged output of the paper is:
- A community-reviewed draft for a low carbon energy ontology in support of metadata,
- Metadata suggestion cards for low carbon energy researchers,
- Recommendations on how to proceed.
Invitation to comment the draft before the writing workshop, e.g.:
- Review of key questions,
- Suggestions of literature, illustrative cases, metadata perspectives & issues,
- Suggestions to any section (e.g., Introduction, Method, Discussion of Results, Outlook)
- Adding snippets of texts,
Any other idea is welcome!
Using above prior comments & contributions provided by 23.11.2020, the EERAdata team will revise the draft before the workshop starts. During the workshop, the discussion & writing of the paper continues in small writing teams. A prior registration to teams is therefore recommended. However, teams can change anytime. The EERAdata team is strongly interested in inviting a large group of contributing authors. It is not only in the interest of the community project as such, but it increases the credibility of the main output - the draft (or road towards) a low carbon energy ontology in support of metadata”.
Co-authorship is granted to active participants of the EERAdata workshop as well as to other contributors to the community paper.
EERAdata wiki - How to?
The easiest way is you simply start writing and editing. You can install an easy editor by doing what is described in the picture to the right.
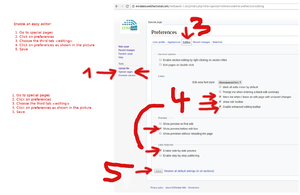
How to install an easy editor
Consult the User's Guide for information on using the wiki software.
EERAdata on github
Link here and share your thoughts and issues! Note, work in progress.
EERAdata @ Research Gate
Link here and share your thoughts and issues! Note, work in progress.
Just have fun!
Metadata memory game
Read before playing: This is a little memory game where players need to identify triples, that is three tiles that belong to one data set. All of them relate to low carbon energy. Some tiles have the form of a picture, others show metadata descriptions (in various formats) and some are even sound files. So, the game is to have fun, while learning about metadata. Try out if you can find all triples. Note if you have opened 3 tiles and they do not match, all will automatically close. Just as you know it from a real-life memory game.
Link
Agenda and notes
Builds on read aheads. Online talks and discussions. Space for interaction with participants after each presentation. Moderated discussion of collected comments.
| Time slot |
Topic
|
| 10.00-10.20 |
Welcome and introduction with workshop goals and procedures: “EERAdata - Towards Utopia for low carbon energy research”, Valeria Jana Schwanitz, HVL & PI EERAdata. Link: [1]. Main points:
- In the energy system the data revolution offers prospects, but we are fare away from harvesting them. The time researchers spent with data governance (finding, cleaning, revising of formats) and bureaucracy exceeds time spent on exciting stuff (thinking, creating new insights, collaborating, and discussing with others) by far.
- There is a lack of joint standards and common metadata formats to support researchers in finding and reusing heterogeneous data. Machine-actionability is also an issue.
- The vision of developing a one-stop-entry point for energy research is clear before our eyes: being able to search for data, access rich metadata, choose & select datasets, crunch data real-time online, being able to link to "My-researcher-space", a platform that offers a personalized workspace for data analysis, paper writing, and research collaboration.
|
| 10.20-12.15 |
Online lectures:
“The EOSC Nordic: machine-actionable FAIR maturity evaluations & the FAIRification of data repositories” - Andreas Jaunsen, Nordforsk & EOSC-Nordic. Link: [2]. Main points:
- Goal and vision of EOSC: Enable researchers to access data across domains and disciplines as easy as possible, support locating the relevant data. All European data should be available to researchers, but this does not mean that all data is stored centrally. Instead, databases should be interconnected.
- FAIR maturity evaluations: Close to 100 repositories have been tested using an automated tool. Most of them only score with 0.10 out of 1.
- FAIR Evaluation Tool: [3]
- EOSC Website: [4]
“OpenAIRE: Open Access Infrastructure for Research in Europe”, Ilaria Fava, OpenAIRE. Link: [5]. Main points:
- Goal and vision of OpenAIRE: To "Bridge the worlds where Science is performed and where Science is published", by monitoring, accelerating and supporting Open access research and publishing.
- OpenAIRE consists of 50 European partners, including 34 National Open Access Desks (NOADs, that provide support on issues related to Open Science Policies, Open Science Infrastucture, Open research Data and Open Access to publications
- Lessons learned: "Research is global, support is local". Regional differences in culture and maturity of open access infrastructure require support strategies specifically tailored to each region.
- OpenAIRE Website: [6]
- OpenAIRE Connect: Platform that allows to connect with the research community of a specific research field [7]
- OpenAIRE Provide: platform that allows open access publishing of Data [8]
- Further Links copied from Conference chat:
- Working Group on Rewards: [9]
- Open Science Policy Platform: [10]
- Clarivate Data Citation index: [11]
A short break of 15 min -
“Community-driven metadata and ontologies for Materials Science and their key role in artificial-intelligence tools”, Luca Ghiringhelli, FHI Berlin. Link: [12]. Main points:
- The attributes of a data object can be data or metadata, depending on the context
- "An Ontology is a formal (= machine readable) representation (= concepts, properties, relations, functions, constraints, axioms are explicitly defined) of the knowledge (= domain specific) of a community (= consensual) for a purpose (= question driven)."
- Definition of FAIR data:
- Findable: unique names, human-readable descriptions
- Accessible: URL, accessible via API
- Interoperable: typed, extensible schema -> ontologies
- reusable: hierarchical schema -> data-analztics
- NOMAD Meta Info: [13]
“Metadata practices from IRP Wind”, Anna Maria Sempreviva, DTU. Link: [14]. Main points:
- Alternative interpretation of FAIR data: Reusability of Data is the final goal with Findability, Accessibility and Interoperability being prerequisites for Reusability. Reusability of Data for multiple purposes multiplies the value of the Data
- Open data = available data <-> FAIR data = findable data
- Issue: How to make data findable but safe (in regards to data protection, competitive advantages, etc)?
- Solution: Create a searchable data catalogue of distributed data
- How to create a taxonomy?
- Expert elicitation: Group of experts creates a taxonomy which is then reviewed by wider research community
- "top-down" approach
- + clearly defined, controlled vocabulary
- - static, unable to adapt to new trends
- Taxonomy based of author keywords: Map keywords used by authors along similarities in meaning, frequency of usage
- "bottom-up" approach
- + adaptable, able to track new trends
- - Mix of disciplines, models, etc; Many errors and ambiguities; single generic words with a broad range of possible interpretations.
- IRP Wind Website: [15]
|
| 12.15-13.00 |
Lunch Break. Play the EERAdata game “Utopia and metadata”. Or any time.
|
| 13.00-14.00 |
Online lectures:
“Humanities and data: for a community-driven path towards FAIRness”, Elena Giglia, UNITO. Re-using presentation held at the Open Science Conference 2020 in Berlin. Presentation stored at zenodo. Link: [16]. Main points:
- The Data Management Lifecycle: Identify research data -> Plan data management -> collect/produce & Structure & Store -> Deposit for Preservation, Cite & Share -> Dissimination
- AT which phase to apply the FAIR principles?
- "There is value and risk at being a first mover (regarding implementation of FAIR principles), but there is a higher risk at being a follower"
- What is data in the humanities:
- Never "raw" data
- Data is always an expression of the method
- there is always a choice ( methodological, epistemological, political,...)
- There is always an interpretation, subjectivity (Data are not generated by a machine)
- there is always a discussion
- preliminary issues of FAIRness:
- what language?
- Lack of skills among researchers
- registry of existing tools
- need to preserve specificity of how we do research in the humanities
- services and tools need to be sustainable
- Time consuming and no incentive or reward to apply FAIR principles
“RISIS - An e-Infrastructure for the STI-Policy research community”, Thomas Scherngell, AIT. Link: [17]. Main points:
- What is RISIS: First pan-European research infrastructure to study research and innovation dynamics and policies
- Set of interlinked databases on: Firm Innovation capabilities, R&D output, Public research and Higher Education, Policy Learning.
- Not all data accessible, but interlinking mechanisms are fully public
- While Metadata descriptions in, for instance, PDF format are not machine readable, it is also important to have a qualitative format such as PDF that is easily understandable by humans, for instance to present your data/ work to the outside.
- RISIS Website: [18]
- RISIS Knowmak tool: Provides Indicators in Key Enabling Technologies and Societal Grand Challanges [19]
- SIPER: Science and Innovation Policy Repository [20]
|
| 14.00-14.30 |
Break - Game “Utopia and metadata”. Or any time.
|
| 14.30-16.00 |
Discussion to compile a to-do list for work in use cases on the second day. Serves as a guiding and aligning process. Lead by WP2, August Wierling/Valeria, HVL. What is the take-to-day-2 message for your use cases?
- Use case 1: The main issue for us is re-usability. We need to assess the databases that were chosen previously. Learn from best practices.
- Use Case 2: Our main issue is privacy/ sensitivity of data. Security should come first. There is a tradeoff between universal metadata language and domain-specific language.
- Use case 3: Linguistics is a problem. As soon as we change the application of the material, we also change related metadata. Find similarities of already existing metadata.
- Use case 4: We face different languages and terminologies. The range of interpretation of the same terms is broad. We should address low hanging fruits but also aim at cracking hard nuts to improve FAIR/O principles.
- General: EERAData is probably more about asking the right questions to the energy research community than providing the right answers. There are already a lot of answers out there, we need to link them to our data issues. We envision being able to suggest low carbon energy metadata standards for and with the research community. Colleagues working on the EERAdata platform will join in on all use case discussions on day 2.
- Motto: "Ontology is a formal representation of the matured knowledge of a community on a specific purpose".
|

